

Full text search is easy to use. But the inherent ambiguity of natural languages causes search results to be biased with false positives. To obtain more accurate results, we need to change the approach and provide more domain specific data to the search engine.
The most common and easiest to improve search results is to introduce filters, i.e. multiple input fields (text fields, radio buttons etc.) named after properties. This way we know how to shape the query and then return specific results. In combination with some approximate string matching algorithms, we may obtain very accurate search results. Unfortunately filters require forms with multiple fields at the cost of simple UX. (see Figure 1).

Figure 1
What if we'd like to stick to a single text field and still have accurate search results (see Figure 2)? Surely one needs to employ natural language processing (NLP) tools. But everyone in the IT industry knows that NLP is hard to master and majority thinks it's a highly academic approach. How can this be easily employed to improve search results over a specific domain?
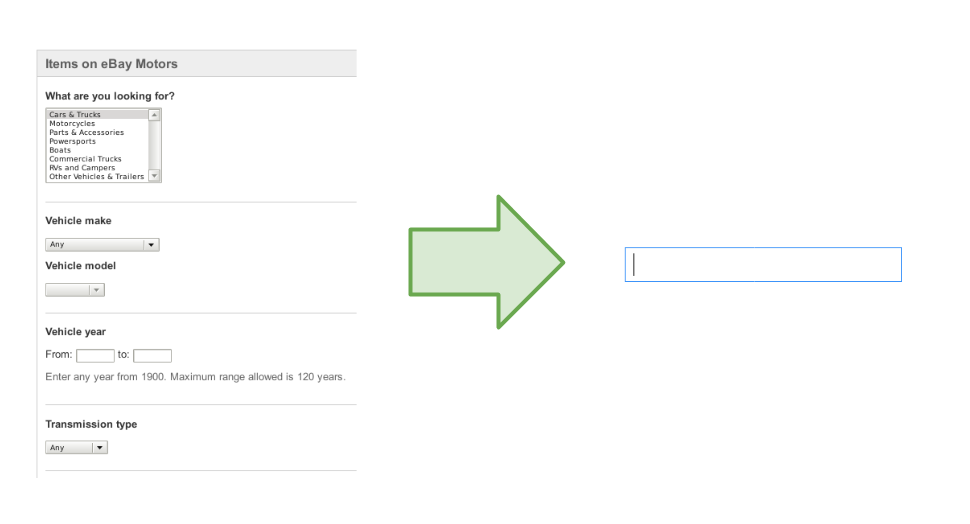
Figure 2
Domain
Specificity of the domain is the key part of the approach. Machine learning algorithms are far from being ready to answer general questions. Even though the algorithms exist, they are far from our reach. For simplicity, we have to narrow the domain. Usually when we are in a need for introducing a search form, we operate within some area, i.e. finding a car at ebay.com we specify the type of the car, year of production, manufacturer, model etc..
For the sake of this article, let's take the domain of film screenings, i.e. tuple of: movie, theater and the date and time. We may also assume we know the geographical location of the theater and genre of the movie. We are going to query the film screening by title (or just genre), theater name (or just location) and date and time that the screening is going to happen - that is the data we need to collect from the user. Sample expressions we'd like to handle:
the martian in san francisco tomorrow - query all theaters in San Francisco that will play The Martian tomorrow,
the revenant in amc next week - query AMC theater for all shows of The Revenant that will occur next week,
cinemark next wednesday - query Cinemark theaters for all the shows that will occur next Wednesday,
drama in san francisco on 11 June - query all theaters in San Francisco for a drama that will occur on 11th of June.
All expressions are transformed from natural language to a query of the form:
case class Query( movie: Option[Either[MovieName, MovieGenre]], theater: Option[Either[TheaterName, TheaterLocation]], from: Option[DateTime], to: Option[DateTime]) case class MovieName(value: String) case class MovieGenre(value: String) case class TheaterName(value: String) case class TheaterLocation(value: String)
Need for NLP
It is hard to extract information from natural language. If we assume that there are just a few kinds of input statements, like [MOVIE_NAME] in [THEATER_LOCATION] [TIME_EXPRESSION], then it might be possible to program the parser for such statements explicitly. But even though someone manages to do this, such an algorithm would be unmaintainable. With NLP tools we may approach this problem without the need to program explicitly.
Moreover, some statements are extremely similar in their structure, e.g.: [MOVIE_NAME] [TIME_EXPRESSION] and [THEATER_NAME] [TIME_EXPRESSION] - it is impossible to unambiguously differentiate both statements. NLP tools also care about the structure of [MOVIE_NAME] and [THEATER NAME], then when extracting the information from statements it has more data to make a decision than the explicit parser.
Description of the solution
For our example the only subtask of information extraction we need is called named entity recognition. Having the statement properly tagged we are able to compose our Query. By tagging we mean assigning some domain specific meta information to each word from the statement, e.g.:
the martian in san francisco tomorrow -> (MOVIE_NAME: the martian) (PREPOSITION: in) (THEATER_LOCATION: san francisco) (TIME_EXPRESSION: tomorrow)
amc next wednesday -> (THEATER_NAME: amc) (TIME_EXPRESSION: next wednesday)
Tools
When trying to tackle the problem, our first attempt was to try the Stanford Named Entity Recognizer, which gave us stunning results, but unfortunately cannot be used commercially because of the GNU GPLv2 licensing.
Finally we decided to use the Epic library from ScalaNLP suite (all licensed under Apache 2.0). Epic has many NLP algorithms implemented, but the downside we encountered is lack of the documentation thus it's usage is far from straightforward.
Sample data
In order to train the Named Entity Recognizer (NER) we need to supply the algorithm with sample data. If we don't have any real life data then we may generate some random statements based on possible schemas, like:
[MOVIE_NAME] in [THEATER_LOCATION] [TIME_EXPRESSION][MOVIE_GENRE] [TIME_EXPRESSION] in [THEATER_LOCATION]
The format of the input depends on the library we use. The academic standard for describing the training data, CoNLL, covers much more than we need. Fortunately there is a way to simplify to just tagging, i.e.:
the MOVIE_NAME martian MOVIE_NAME in PREPOSITION san THEATER_LOCATION francisco THEATER_LOCATION tomorrow TIME_EXPRESSION comedy MOVIE_GENRE thursday TIME_EXPRESSION evening TIME_EXPRESSION in PREPOSITION san THEATER_LOCATION francisco THEATER_LOCATION
The optimal size of the training sample depends on the complexity of the domain and should be verified empirically.
You can check the example at GitHub how we generated sample data.
Training NER
We need to encode the relationships between the tagged statements and then construct some consistent interpretations for further reuse. Statistical tools that solves this problem are called conditional random fields (CRFs). In ScalaNLP there are two implementations of CRF available. The first one epic.sequences.CRF is the ordinary linear-chain CRF and the second one epic.sequences.SemiCRF is an implementation of semi-Markov linear chain that should have better performance at small cost of accuracy.
Load input data into sequence reader
ScalaNLP has built-in parser for CoNLL data - epic.corpora.CONLLSequenceReader which accepts the data input we proposed in section Sample data.
var sequenceReader = CONLLSequenceReader .readTrain(dataSetInputStream) .toIndexedSeq
Apply segmentation function
We train the CRF by transforming the input data to epic.sequences.Segmentation[Any, String]. The segmentation is grouping the same tags in a row.
val seq = sequenceReader.map(segmentation)
the segmentation function we use:
def segmentation(ex: Example[IndexedSeq[String], IndexedSeq[IndexedSeq[String]]): Segmentation[Any, String] = { val segments = ex.label.foldLeft(List.empty[(String, Int, Int)] { case (acc, label) => acc match { case head :: tail => head match { case (`label`, beg, end) => (label, beg, end + 1) :: tail case (nextLabel, beg, end) => (label, end, end + 1) :: head :: tail } case Nil => List((String, 0, 1)) } val segmentsSeq = segments .reverse.map { case (label, beg, end) => (label, Span(beg, end)) } .toIndexedSeq Segmentation(segmentsSeq, ex.features.map(_.mkString), ex.id) }
Build CRF
having the input segmented, we can build the CRF:
val crf = SemiCRF .buildSimple(seq) .asInstanceOf[SemiCRF[String, String]]
Use the trained crf for tagging sequences
val taggedSequence: Segmentation[String, String] = crf.bestSequence(epic.preprocess.tokenize(inputString))
epic.preprocess.tokenize is just tokenizing by whitespace.
The Segmentation carries the tagged sequence. When we render a sample expression we get a string with tagged segments:
[MOVIE_NAME: the martian] [PREPOSITION: in] [THEATER_LOCATION: san francisco] [PREPOSITION: on] [TIME_EXPRESSION: 11th June 2016]
With such a tagging we are almost ready to construct the Query. The only missing part are the TIME_EXPRESSIONs. We need explicit from and to parameters of type DateTime. We may use PrettyTime::NLP to parse explicit time expressions, like: 11th June 2016, but if we want to obtain something more sophisticated, like next Wed or tomorrow we should employ the NLP approach again, i.e. training the CRF for time expressions.
The results are pretty astonishing. The crf, once trained, is working instantly. The accuracy of the interpretation will vary depending on the complexity of the domain and size of the training sample. In our case, we were surprised about the accuracy - even for ambiguous statements, the crf was doing well.
For the sample size of 200K input statements (generated with simple-ner-search-dataset-generator, we've trained the NER with ner-trainer, and get the following results:
the martian in san francisco tomorrow [MOVIE_NAME: the martian] [PREPOSITION: in] [THEATER_LOCATION: san francisco] [TIME_EXPRESSION: tomorrow] (in 8 ms) the revenant in amc next week [MOVIE_NAME: the revenant] [PREPOSITION: in] [THEATER_NAME: amc] [TIME_EXPRESSION: next week] (in 15 ms) cinemark next wednesday [THEATER_NAME: cinemark] [TIME_EXPRESSION: next wednesday] (in 2 ms) drama in san francisco on 11 june [MOVIE_GENRE: drama] [PREPOSITION: in] [THEATER_LOCATION: san francisco] [PREPOSITION: on] [TIME_EXPRESSION: 11 june] (in 4 ms) amc next wednesday [THEATER_NAME: amc] [TIME_EXPRESSION: next wednesday] (in 2 ms) the martian in san francisco on 11th june 2016 [MOVIE_NAME: the martian] [PREPOSITION: in] [THEATER_LOCATION: san francisco] [PREPOSITION: on] [TIME_EXPRESSION: 11th june 2016] (in 8 ms)
You can check this yourself in the interactive session by installing the ner-trainer and loading the serialized example by calling:
ner-trainer -l film-screenings.tar.gz
Tradeoffs
Unfortunately training the CRF is extremely time consuming (measured in hours). There is a need to serialize the SemiCRF object in order not to waste time. The serialization comes at the cost of taking care of binary compatibility. Also SemiCRF might be a quite heavy object, so there comes the cost of additional memory.
The Epic library is not easy to use. The documentation is not very helpful, and also lacks serious static typing. Even in this short example we were not able to avoid asInstanceOf.
Conclusions
The libraries that are currently available nicely cover the hard parts of the problem. The tradeoffs are possible to overcome and many of them are relatively easy to fix, so probably will disappear in the future. Nevertheless it is possible to construct quite sophisticated NLP based search without drowning in complicated math. Even the newcomer should be able to implement the search in a matter of days.
URLs
ScalaNLP: http://www.scalanlp.org/
Stanford Named Entity Recognizer: http://nlp.stanford.edu/software/CRF-NER.shtml
PrettyTime::NLP: http://www.ocpsoft.org/prettytime/nlp/
NER Trainer: https://github.com/evojam/ner-trainer
Film Screenings Data Set Generator: https://github.com/evojam/simple-nlp-search-dataset-generator
All of you feel invited to checkout and hack with NER trainer and data set generator on your domain. Please provide feedback in comments how this approach is working for you.