

Do we need any more Patterns?
Design Patterns are often described as typical solutions to common problems. But what if a solution is not that typical? Can I still call it a Pattern if it is only relevant for relational databases? And does it have to be applicable in most common Java stacks using Spring Boot, Hibernate, and JPA?
Alternatively, anti-patterns are approaches that seem like a good idea in the beginning but cause a lot of problems in the end. This seems more precise and, annoyingly, summarises all the code or SQL queries I have ever written.
Temporal Patterns, as catalogued by Martin Fowler in 2005, are just like any other Patterns in software development — they need some getting used to, they cause you some trouble in the beginning, and they have a proven record of being a good idea in the end. We will try to see if Temporal Patterns work well in case of Spring Boot code using Spring Data as well as some custom SQL to handle data access to temporal changes in your database.
Does Spring Data need Temporal Patterns?
When using a relational database, questioning any SQL DELETE operations in production is fairly common. How do you revert a DELETE when a user account needs to be restored? Naturally, you do not actually delete a table row in the first place, you set a status column to `deleted`. So what do you do when a user’s first name changes but its previous value is not something that is never going to be asked?
We have all heard about event-sourcing as a pattern by now. Let me be the first to admit it — I have never implemented it in any form. It comes at a certain cost and has its overhead and complexities.
This is not to say that I have not seen numerous scenarios where SQL UPDATE operations could not overwrite previous values. It is just that in all those cases storing all changes in my domain would have been clear overkill. Mostly when the scope of changes that need to be auditable was highly constrained.
Is it going to work with Spring Boot?
Let’s look at an imaginary Spring Boot project with no obvious data versioning requirements. We are supposed to implement a system for a comedy agency, keeping an inventory of Comedians and Jokes that Comedians use in their daily work. The competitive advantage is going to come from Reaction recording and analysis capabilities. Every time a Joke is told either the Comedian herself or an appointed specialist in the audience is going to send us a number between 1 and 10, representing the level of enthusiasm for a particular Joke on a given day.
Two key REST endpoints underlying this functionality are going to be:
1. HTTP POST /joke/{uuid}/reaction— to record and persist Reactions in a database;
2. HTTP GET /joke/{uuid}/reaction — to view historical (and hopefully hysterical) Reactions.
This seems fairly straightforward — all it takes are three tables for Comedians, Jokes, and Reactions with two @ManyToOne relations set up using Java Persistence APIs (JPA):
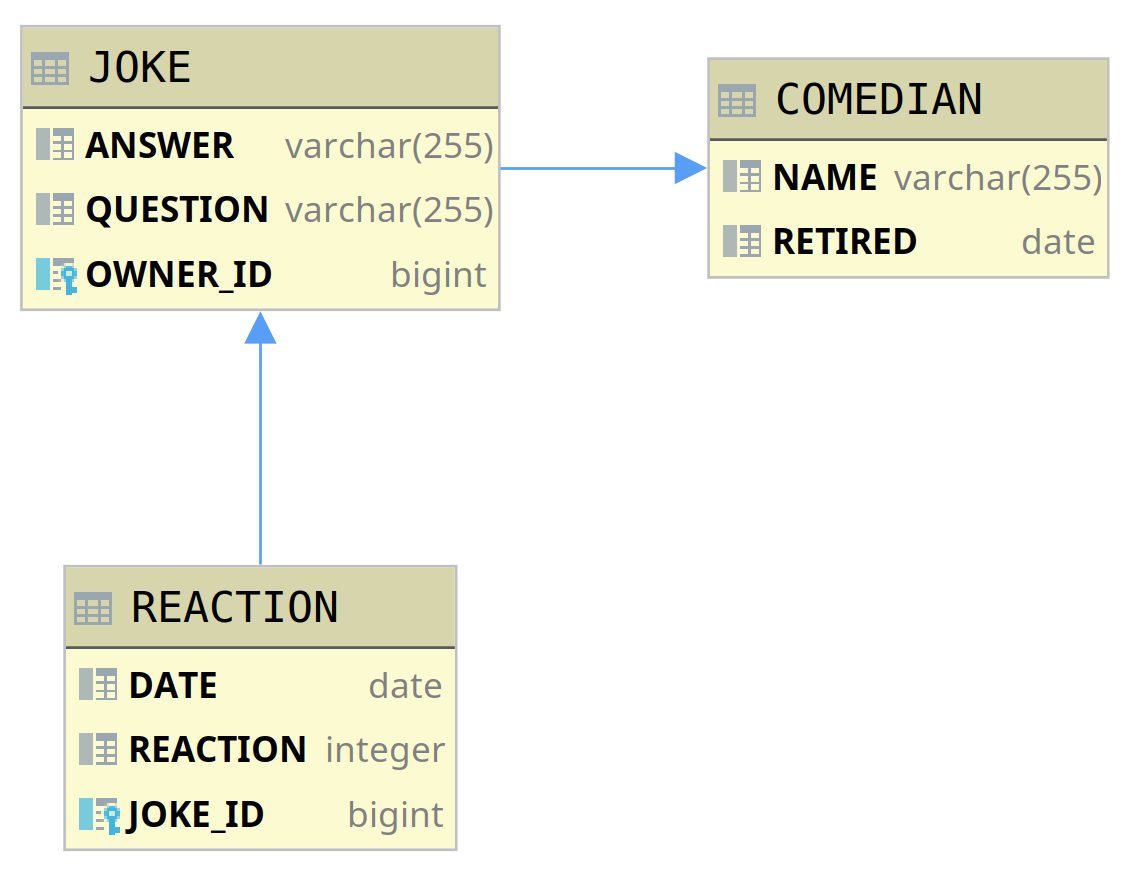
We are almost done with our Spring Data code, there is just one more capability that the system needs to have and that is changing the question part of each Joke and storing it in the relational database. This is because based on Reactions all Comedians tend to fine-tune their Jokes. So to do that we need one extra endpoint:
3. HTTP PATCH /joke/{uuid}— to make a change to a joke.
No big deal! We go ahead and add it in a matter of minutes. It is exactly the type of task that Java technologies like JPA are made for:
@PatchMapping("/joke/") void rephrase(@PathVariable UUID uuid, @RequestBody RephraseDto request) { jokeRepository.findByUuid(uuid) .map(joke -> joke.setQuestion(request.getQuestion())) .ifPresent(jokeRepository::save); }
It is only when the users start utilising these endpoints that they realise what they are seeing based on database contents is not telling the full story. Say a Joke gets two reactions:
POST /joke/3edd9cf0-783a-4e6c-bb98-a406f80048e4/reaction [ { "date": "2020-12-31", "reaction": 4 }, { "date": "2021-01-06", "reaction": 4 } ]
Followed by a change to how it is supposed to be told:
PATCH /joke/3edd9cf0-783a-4e6c-bb98-a406f80048e4 { "since": "2021-01-13", "question": "What did the fish say when it hit a wall?" }
Followed by more lively Reactions:
POST /joke/3edd9cf0-783a-4e6c-bb98-a406f80048e4/reaction [ { "date": "2021-02-12", "reaction": 9 }, { "date": "2021-03-01", "reaction": 8 } ]
Now when the data science department of the enterprise use historical reactions from the Spring Boot application, what they see looks somewhat mysterious:
GET /joke/3edd9cf0-783a-4e6c-bb98-a406f80048e4/reaction [ { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2020-12-31", "reaction": 4 }, { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2021-01-06", "reaction": 4 }, { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2021-02-12", "reaction": 9 }, { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2021-03-01", "reaction": 8 } ]
How come the same Joke suddenly went from 4’s to 9’s and 8’s? Does it really depend on the crowd? Did the Comedian change her haircut sometime in January and now she is more appealing?
We kind of know the answer — in the first two events it was not genuinely the same Joke. The “question” was changed on January 13rd but because using Spring Data we executed an SQL UPDATE on a table row, there is no way of telling! We were supposed to record historical data and in the process, we erased relevant information.
How to get started with Temporal Patterns?
Temporal Patterns catalogued by Martin Fowler back in 2005 are a set of handy data modelling alternatives to crude updates. Most use cases stem from circumstances where one needs “to answer questions about the state of information in the past.” These could be the user's privacy settings that let us nudge her with push notifications at a given point in time. Or data points like the person’s marital status that influenced particular insurance calculations and for audit reasons shall not be just overwritten.
Looking at Temporal Patterns, most of them share a common characteristic of working with time ranges, represented by pairs of dates specifying the start and the end of `effectivities` for certain values. The exact names we give them are irrelevant, “from” / “through” is as good as “since” / “until.” What is more important, is being consistent with the way we represent infinity in the relational model. Many times as far as we know a value will be in effect indefinitely. When a user registers as married on February 2nd, we know the “since”, but we also need to ascribe a value to “until”. The approach we are going to take in this example will be using “null” for that purpose.
One more thing to keep in mind is the types of Commands and Queries that we are expecting. Temporal Patterns do not assume much command-query separation. What you write to the database with SQL INSERT is essentially what you read with SQL SELECT, which implies relative parity of changes against views and no need for optimization for either data access category. We are talking about elemental CRUD queries, but let’s be honest, not all of us are designing the next eBay or Netflix.
What do they have to do with Spring Data?
Enough talk, we have some not-good-enough code to fix. Jokes keep changing by means of the PATCH endpoint that we exposed with Spring Data and Spring Boot. What we have learned is that issuing UPDATE queries against the Joke table erases previous row values. In that case, we can start treating every Joke like a Temporal Object, which it is — pulling out the changing “question” column to its own table, along with “since” / “until” range markers. Now the relational model is going to be:

It means that for each new PATCH existing relations between the Joke, Comedian, and Reactions data will remain intact. All handling will happen in the Joke Versions - the previous latest row will be updated with an “until” and a new row will be inserted. Both can be implemented inside the new JPA @Entity class:
@Entity @Data @Accessors(chain = true) class JokeVersion { @ManyToOne Joke joke; String question; LocalDate since; LocalDate until; Stream<JokeVersion> rephrase(String question, LocalDate since) { this.until = since; JokeVersion next = new JokeVersion() .setJoke(this.joke) .setQuestion(question) .setSince(since); return Stream.of(this, next); } }
While the updated caller method can work as follows:
@PatchMapping("/joke/") void rephrase(@PathVariable UUID uuid, @RequestBody RephraseDto request) { JokeVersion current = versionRepository.findByJokeUuidAndUntilNull(uuid); current.rephrase(request.getQuestion(), request.getSince()) .forEach(versionRepository::save); }
One last thing to take care of is the way we query Reactions to respond to the GET requests. This part is not as mindless as before, our question to the data model has evolved. The latest query in the Joke table is not good enough anymore, we now need to check what it was at the time of the Joke being told. Luckily, we have all the past values, we just need to connect the dots. As we JOIN rows, the Reaction date has to fit into one of the “since” / “until” time ranges of Joke Versions. This definitely requires us to write a custom JPA @Query beyond queries generated by Spring Data queries:
@Query("SELECT new ReactionDto(" + " comedian.name," + " version.question," + " joke.answer," + " reaction.date," + " reaction.reaction" + ")" + " FROM Reaction reaction" + " JOIN reaction.joke joke" + " JOIN JokeVersion version" + " ON version.joke = joke" + " AND reaction.date >= version.since" + // (1) " AND (" + " reaction.date < version.until" + // (2) " OR version.until is null" + // (3) " )" + " JOIN joke.comedian comedian" + " WHERE joke.uuid = :uuid" ) List<ReactionDto> findByJokeUuidAndQuestionAtTheTime(UUID uuid);
Notice how the JOIN condition marked with (1) makes sure that the Joke Version was introduced before the Joke was told and caused the Reaction. Subsequently, condition (2) excludes any later Joke Versions, which only came into the picture after that particular performance. Finally, condition (3) covers the case of performances working with the latest Joke Version so far.
With this implementation in place the same series of events starts making more sense:
GET /joke/3edd9cf0-783a-4e6c-bb98-a406f80048e4/reaction [ { "jokeQuestion": "What did the fish say about a wall?", "jokeAnswer": "Dam!", "date": "2020-12-31", "reaction": 4 }, { "jokeQuestion": "What did the fish say about a wall?", "jokeAnswer": "Dam!", "date": "2021-01-06", "reaction": 4 }, { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2021-02-12", "reaction": 9 }, { "jokeQuestion": "What did the fish say when it hit a wall?", "jokeAnswer": "Dam!", "date": "2021-03-01", "reaction": 8 } ]
Succinct application of the Temporal Object Pattern helped us eliminate inadvertent data loss! Reluctant as we are to ever truly DELETE hard-earned information in production, bypassing such requirements with all forms of status fields set to ‘deleted’, the third letter of CRUD acronym is no less notorious for erasing our knowledge of the past! Use it with caution.
Time cost or time savings?
A good understanding of Temporal Patterns gives you an upper hand in modelling historical changes in your domain. Like you saw in the Jokes example with Spring Data, they do require to be tailor-made for your specific use case, which is not a bad thing — their resilience lies in their flexibility. It is not fully feasible for any library or framework to provide a comprehensive implementation. But fear not, as we have seen in the example above, elementary JPA features can give you significant leverage.
Another way to look at these Patterns, just like any Patterns for that matter, is as excellent time-savers. Surely, they will cost you some effort to put in place as you get started. Once you get past that point, the investment will pay dividends time and again.
Try it for yourself!









