


At Evojam we always seize opportunities for R&D. So when a former client asked us for cooperation on an existing project, which involved a 1 billion member social network, we jumped at the opportunity. We joined the team and did our best to fix bugs and solve data consistency, performance and reliability issues. Additionally, we presented a more effective approach to the application’s architecture. This article briefly covers our journey through the 1 billion member social network.
This story has been initially told at the Scalar 2016 conference in Warsaw. Slides from that presentation are available on Slideshare.
Challenge description
A social network can be easily represented by a graph structure thus I will use these terms interchangeably through the article.
Graph structure and business value
This particular graph consisted of User and Company vertices connected with two types of relations: knows and worked. Knows relation links User vertices and represents existing connection between two user profiles. Worked relations describes work history for user thus connects User vertex with Company. For the sake of simplicity we have assumed that the graph is undirected.
The core idea of the application is to provide a subset of the graph that will be fulltext searchable, filterable and sortable in near realtime.
To describe the algorithm which defines the subset we will follow an example. If we assume that we are going to present results for Foo Inc., we traverse from the Company vertex through worked relations and further through knows relations to the final User vertices.

The real data size for the graph was slightly smaller than expected at the beginning, though still challenging. Whole graph consisted of 830 millions of vertices and almost 7 billion relation. Final subsets for fulltext searching varied in size from few thousand to a few million.
Existing app
The existing application stored all data, including 750 million profiles, 80 million companies and 7 billion relations in Amazon Redshift. Generating the subset took few days from the enduser perspective. Technically the whole process was handled manually with set of batch scripts and required pulling subsets from Redshift to JSON files, pushing to MongoDB and further to Elastic Search. We have decided to suggest something much more reliable and corresponding to real product requirements.
Proof of Concept
To provide the impression what can be achieved with Scala and validate our concept we have decided to build PoC implementation on fully anonymized data.
The goal
The primary objective was dead simple: handle 1 billion social network automatically. We have specified the Definition of Done for the PoC as working application, exposing the REST endpoints that allow us to run fulltext searches on the subset. It has to be generated on the fly for an arbitrarily chosen customer. Additional solution requirements that we have decided to impose:
First results from the subset must be available in under 1 minute
Entire subset has to be ready for the end user in few minutes
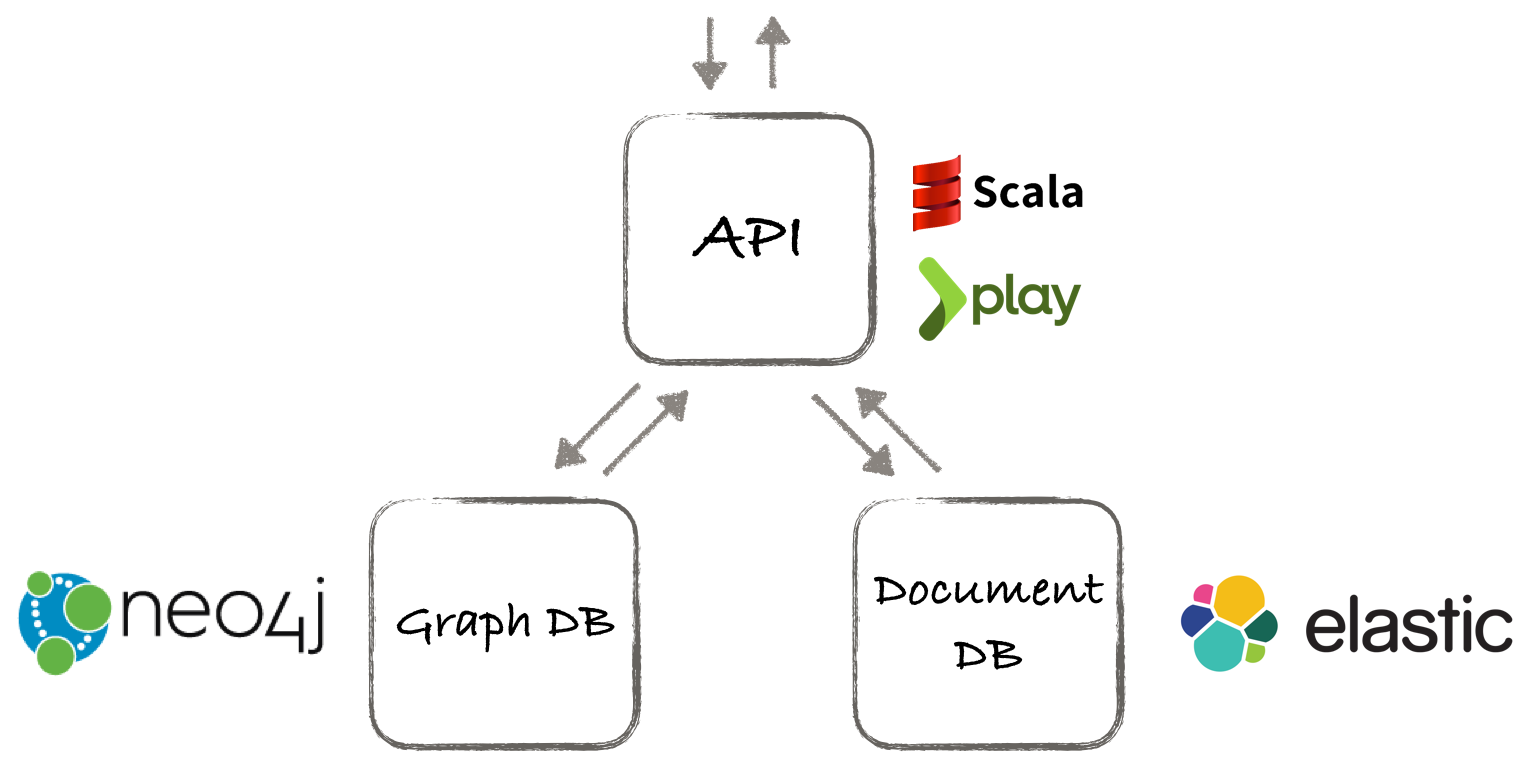
Architecture concept
We have decided to build a simple application that would store data in two database engines: graph database for all vertices and relations, without any properties and document database with fulltext search with all profiles' data. On demand we would run graph traversal in the database and fetch vertices ids. Response for the graph query will be streamed to the api application and used to tag existing documents with a unique token in the Search Engine. Finally, the token can be used to select only profiles belonging to the subset during the search queries.
Weapon of choice
We have decided to use Play Framework with Scala to build the application. We already had an idea which document database will suit us the most. Having significant experience with ElasticSearch though the choice was quite obvious. Elastic perfectly scales horizontally and allows extremely resilient cluster configuration. Additionally the documentation is very clear and exhaustive.
On the other hand the graph database engine was not an easy choice. We had to make few experiments. The database engine we have considered were Titan, OrientDB and Neo4j. We pulled a fully anonymized graph from the source Redshift database into CSV files, cleaned them up and started the Graph Databases evaluation.
Titan, which is built on top of Cassandra and Elastic Search, performed quite well. Unfortunately it seems that the project developments have been put on hold. OrientDB was not very performant during initial load, additionally it refused to work after 200-300 million vertices and relations - we could read data but write requests were not parsed and no errors were reported. Only database restart could temporarily resolve the issue. We have dug through a plethora of blog posts describing various horror stories with OrientDB. The last man standing and an implicit winner was Neo4j.
AWS setup
We have decided to launch the PoC on AWS. Instance for the API was quite modest (m4.large which has only 2 vCPUs and 8GB of RAM). Neo4J have been launched on rich in resources i2.2xlarge (8vCPU and 61GB of RAM which also ensures high network performance). For the Elastic Search cluster we selected two i2.xlarge instances. Unfortunately both m4.large and i2.xlarge have only moderate network performance. On Elastic Search the shard replication has been disabled for the PoC scope.
Loading data
Bulk loading into Neo4j
We have used the importing tool bundled with Neo4j to feed the database. It's an offline import mechanism which uses almost all given resources and thus provides enormous throughput. We have been able to import whole graph of 850 million vertices and almost 7 billion relations in 3.5h.
Feeding ElasticSearch
ElasticSearch has no bundled tool for batch insertion from CSV. Additionally we had to enrich our vertices, which until this stage were some meaningless numbers, with some fulltext searchable data. For each id we wanted to generate:
first name from database of 2000 popular names
last name from frequent US surnames
email
avatar as an url.
Usually it's tough to utilize more than one cpu for such a task. When processing text file we often end up working in a line by line fashion. This time we have built a simple tool with Akka Streams. Akka and Scala made parallelization super easy thus we had much better utilization of multiple vCPUs. All profile data was generated in multiple threads.
With Akka Streams the id processing and bulk pouring into ElasticSearch was not only fast and efficient but also extremely human readable. I love the simplicity and legibility of this kind of approach for description of data flows.
API Implementation
Tagging
To implement tagging we had to:
Execute graph traversal in Neo4j
Stream result ids to API
Update documents in Elastic Search
Again, Akka Streams came to the rescue. With first implementation we have pinpointed and solved basic issues:
When the Neo4j streaming endpoint is not consumed fast enough, Neo4j drops the connection. It's quite obvious but out of the scope of this article. To solve this we have added a buffering stage to the stream.
There is a mysterious bug in the underlying implementation, either of Neo4J client library or Play Enumeratee to Akka Stream wrapper - the stream never ends. My wild guess is that there is no EOF sent to the Enumeratee. Fixing this issue was out of the scope of the PoC thus we have implemented custom buffer with timeout. This has saved us a lot of time while having a schedule more than tight enough.
This naive implementation with indexing documents one by one allowed us to tag (in fact update) documents in Elastic Search with a rate of 670/s. For a dataset of 2 million it would take 1.5h - still much more than the accepted limit. We have made minor change, grouped update request and executed them in bulks of 20,000. The gain on performance was unbelievable - we have easily hit rate of updates at almost 6000/s.

With this implementation we could have first batch available in 14 seconds and a sample subset of more than 2 million user profiles ready in 7 minutes.

Searching
With all documents from the subset tagged the searching part was as easy as pie. We have prepared the REST endpoint returning 50 profiles matching the fulltext search (sample request: GET /users?company=foo-company&phrase=John). To make this test more relevant we prepared a list of 2000 phrases matching the database with fulltext search. After benchmarking the endpoint with 50 concurrent users we have achieved a stable average response time of 140ms. Internally Elastic Search had constant search rate and very low latency.

Final results
The objective, which we're proud of, has been achieved in a month. Simple table makes it crystal clear that we have chosen right tools and path.
| reference implementation | PoC |
|---|---|
| manual | automatic |
| few days | 14 seconds |
| few days | 7 minutes |
| ~40 millions | ~750 millions |
| no analytics | GraphX ready |
Dealing with datasets of this size is achievable given tools available today. However doing so reliably and successfully requires some research and planning. As among a plethora of possibilities, only a few have what it takes to perform at this scale.
It's worth trying but we don't always have social network data at our fingertips. Here the Stanford Stanford Large Network Dataset Collection from SNAP project comes to the rescue. You can find a variety of real life anonymized graph data samples, including social networks.
You may want to check Tackling a 1 Billion Member Social Network on Slideshare for more diagrams.